|
|
| Basic Hypertext, July 1992 |
|---|
The Web was designed as a novel combination of two existing technologies, hypertext and the internet. Tim Berners-Lee realised that with a simple hypertext format, one could do much. He created HTML as a substrate hypertext format to weave all things on the web together, and based it on an internal format called CERN SGML.
Between September 1990, when the Web code was first written, and late 1992 when the first HTML standardisation efforts started, HTML was loosely defined. This article documents that period, especially the years 1990 and 1991, covering what it calls colloquially the Proto HTML period, before the publication of the two Internet-Drafts in mid-1993 that are generally regarded to represent the first standardisation attempt, HTML 1.
In other words, this article tracks the progress of the format from a quick hypertext hack developed out of an SGML based precursor, to the first serious attempts to codify and develop the same. It is important to realise that since HTML was yet to be standardised, Proto HTML is not one specific format, but an evolving and dynamic format with differing implementations and still nascent design considerations. Despite this, this early phase of HTML was surprisingly consistent in general.
One of the best ways to find out how Proto HTML was composed is by looking at available files from the period. There are several corpora of early files, e.g. the well known contents of hype.tar, and by analysing them with a simple script it's possible to see, for example, which tags were in use in what periods.
To perform this test I assembled some of the corpora, ran a fairly naïve Python script over them to extract frequency counts of the data in JSON format, and then fed them into a Protovis Javascript program to represent the data as a variable scatter plot.
The results show not only which tags were in use in which periods, but also the waves of activity upon the WWW project pages. It's important to realise that the modification times of files were used, so the bubbles correspond to the last possible date on which the content, including the tags, could have been added to the files.
Though what are referred to as tags would later be more properly referred to as elements, the term tag is used very commonly in the early HTML literature, and is therefore retained here. The tags are ordered by frequency of use. Closing tags were ignored.
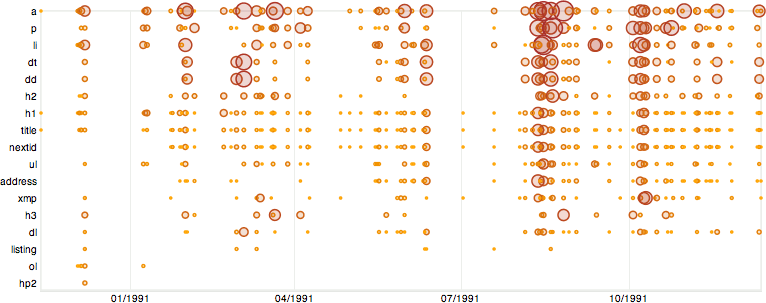
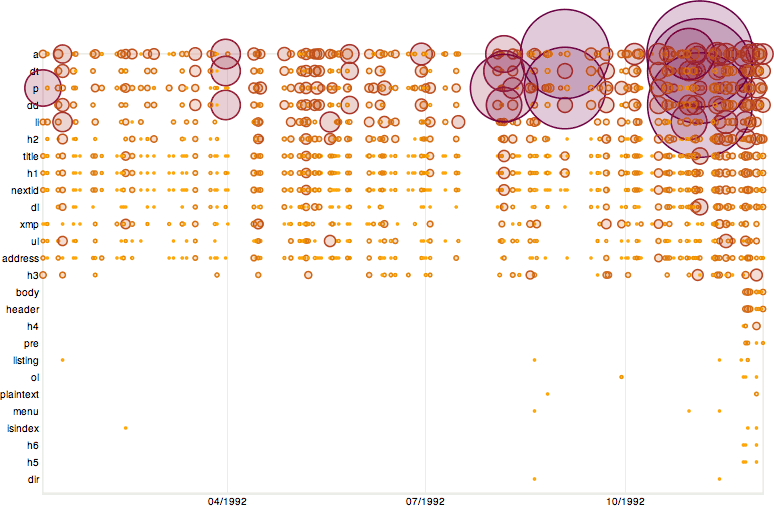
There were 14 reasonably common tags used in 1990 and 1991, and 17 overall including LISTING, OL, and HP2. All of them were used very early on, except for ADDRESS and NEXTID. The later introduction of NEXTID is easy to explain since it was a mechanism really only used to assist the NeXT client in its editing capacity. The late introduction of ADDRESS may simply be a skew feature from the use of modification times, or a late choice in what to include in HTML.
The use of HP2 is limited, I believe, to the early porting of a CERN SGML, SGMLguid, manual into HTML. One very interesting feature is the early use of OL, which goes out of fashion and then comes back towards the end of 1992, perhaps when its utility was realised.
There were two places where Proto HTML could said to be defined. One was in documentation, the other in code. In a careful environment, documentation and code would match, but in the hectic early days of the web with the innovation taking place, this was of course not so.
The descriptive surveys of Proto HTML show the actual usage patterns by the document authors, but they don't show the full range of constructs that were allowed by the documentation and code. To ascertain which tags formed this fuller repertoire, which has always been in tension with usage patterns, I did a survey of the two earliest codebases and earliest HTML documentation.
MarkUp.wn in the following table refers to the earliest known description of the content of HTML, probably dating from the end of 1990, though the circumstances of its creation are a mystery. NeXTStepEditor refers to Tim's 2 Apr 91 HTML parser. Line Mode refers to Pellow's 20 Aug 91 parser. Tags.html refers to the text copy of the first HTML documentation page, the page that started off as MarkUp.wn, from 9 Jan 92.
| Tag | CERN SGML Oct 86 | MarkUp.wn c.1990 | WWW NeXT 2 Apr 91 | Line Mode 20 Aug 91 | Tags.html 9 Jan 92 |
|---|---|---|---|---|---|
| A | Y | Y | Y | Y | |
| ADDRESS | Y | Y | Y | ||
| AVAILABLE | Y | ||||
| DATE | Y | Y | |||
| DD | Y | Y | Y | Y | Y |
| DL | Y | Y | Y | Y | Y |
| DT | Y | Y | Y | Y | Y |
| H0 | Y | Y | |||
| H1 | Y | Y | Y | Y | Y |
| H2 | Y | Y | Y | Y | Y |
| H3 | Y | Y | Y | Y | Y |
| H4 | Y | Y | Y | ||
| H5 | Y | Y | Y | ||
| H6 | Y | Y | Y | ||
| HP1 | Y | Y | ? | Y | not used |
| HP2 | Y | Y | ? | Y | not used |
| HP3 | Y | ? | |||
| I1 | Y | junk | |||
| ISINDEX | v2 | Y | Y | Y | |
| LI | Y | Y | Y | Y | Y |
| LINK | Y | ||||
| LISTING | Y | Y | Y | ||
| NEXTID | Y | Y | |||
| NODE | Y | not imp. | |||
| OL | Y | Y | Y | Y | not used |
| P | Y | Y | Y | Y | Y |
| PLAINTEXT | Y | obs. | Y | Y | |
| RESTOFFILE | junk | ||||
| RTF | Y | ||||
| TITLE | Y | Y | Y | Y | Y |
| UL | Y | Y | Y | Y | Y |
| XMP | Y | Y | Y | Y | Y |
There are 23 tags in the table which were defined in at least half of the surveyed documents and code:
A, ADDRESS, DD, DL, DT, H1, H2, H3, H4, H5, H6, HP1, HP2, ISINDEX, LI, LISTING, NEXTID, OL, P, PLAINTEXT, TITLE, UL, XMP
This is probably a reasonable metric for establishing a core tag set for Proto HTML. Some of the less well known tags, especially NODE and RTF, are still interesting perspectives on the kinds of things that TimBL was thinking about in the early days of the web. NODE is somewhat like <article> from HTML5.
Of these core 23 tags, all were used in 1990 and 1991 quite commonly, except for HP1, HP2, LISTING, and OL, used only rarely, and H4, H5, H6, ISINDEX, and PLAINTEXT, which weren't really used at all. The headings were likely not used because not many complex documents were written. ISINDEX was unlikely to come up when the documents being surveyed are static. The lack of PLAINTEXT is surprising. I assume that this was a more experimental feature, and that in practice XMP, or occasionally LISTING, was more likely to be used.
The oldest record of the structure of HTML is a mysterious early file called MarkUp.wn. This file eventually evolved into one called HTML Tags, but the earliest known version of that is from 9 Jan 92, and MarkUp.wn probably predates it by over a year. It wasn't part of HTandCERN.wn. The MarkUp.wn file contains three versions of itself, so ISINDEX was introduced during its revision.
Since NEXTID and LISTING, which MarkUp.wn doesn't include, were in use in the first quarter of 1991, this file must be ancient. NEXTID was first used on 23 Jan 91 in ECHT90/Authors.html, whereas LISTING was in use in backup_of_test.html on 7 Dec 90, and compact.style on 15 Feb 91. Another sign of the age of this file may be the fact that A is spelled ANCHOR in the LINK section. Moreover the AVAILABLE, LINK, and DATE elements are all unknown, except from this file. The NODE element does appear in the first public release of Tim's browser and editor in August 1991. These factors all point towards this file having been edited in the end of 1990 and beginning of 1991.
ISINDEX is implemented in WWWNeXTStepEditor_0.12's ParseHTML.h of 2 Apr 91, and appears in Release_b2.html in hype.tar which dates to 5 Aug 1991. The change in MarkUp.wn probably predates any appearance of ISINDEX. However, the fact that it was introduced meanwhile is puzzling. It's a shame that ISINDEX is very difficult to track in early files, because it would only be served in dynamic files. Perhaps it was added in connexion with the CERN phone book being put on the web.
One big change is the migration from an ID attribute to a NAME attribute on the A element between versions 02 and 03. The NAME attribute is used the earliest in backup_of_test.html and Xanadu.html from 7 Dec 90, whereas ID isn't used at all. This, coupled with the lack of LISTING from 7 Dec 90, means that the first layers of the document probably predate 7 Dec 90. Another interesting thing is that version 03 contains a hypertext link to Terms.html, which means that revision presumably postdates late Sep 90. At some point REL changed to TYPE, but there isn't enough evidence about when this change happened to be useful.
The fact that TimBL is using vxcern.cern.ch for his email instead of nxoc01.cern.ch may mean that Mike Sendall, TimBL's boss at CERN, was yet to okay the project and allocate that server. I believe that this happened in late Sep 90, when TimBL started writing the code. This may indicate that the earliest version of MarkUp.wn was written between the early FIND paper and the first code, some time most likely in Sep 90; but this is conjecture. What does reinforce this is the use of WriteNow, which TimBL used only until, as far as I can tell, 12 Nov 1990 for the new web proposal.
I've attempted to reconstruct the earliest form of MarkUp.wn.
Subsequent versions of Line Mode:
Of some interest is Bernd Pollermann's 17 Feb 92 session output, using the brand new Line Mode 1.2 ("Version: LMB 1.2"), which seems to have been having memory problems. Interestingly, the core dump of the session contains USER=jfg, so he seems to have been using Jean-François Groff's term.
There is no direct evidence as to when DIR and MENU were added to Tags.html, but there is some circumstantial evidence. They appear in the first HTML DTD of 6 Jun 92, and DanC cites Tags.html in the next version of the DTD, so he probably derived them straight from Tags.html rather than making them up. If this is correct, they were added between 9 Jan 92 and 6 Jun 92. In that period, TimBL happens to mention first MENU and then DIR on two consecutive days, 25 and 26 May 92, on www-talk. This is perhaps evidence that these tags were added around that period. Why they were added, though, is harder to say. There is no direct evidence I can find of why it is thought these additions were required.
Known revisions before the 3 Dec 92 RCS version, from the 24 Nov 92 change list:
Some suggestions by Carl Barker:
HTML was probably named before the WWW, the former by mid Oct 90, and the latter by the end of Oct 90.
HTML was named at least by 12 Oct 90:
F HyperBrowser HyperBrowser app S .html HyperBrowser .html
(NeXT/Implementation/HyperBrowser.iconheader)
This shows that the main NeXT implementation, the first web browser, was originally called HyperBrowser, and was set to handle all HTML files, which had therefore already been named. This is the earliest reference to HTML that I've found, but not the earliest to HyperBrowser: in a file accompanying a very early paper (/FIND/Hyperizing_FIND.wn/WNGraphic.204851.eps), a demonstration client is called HyperBrowse, and this dates to 16 Aug 90.
It seems likely that the name "WWW" was yet to be chosen on 12 Oct 90, otherwise HyperBrowser would probably already be called WorldWideWeb as it was subsequently. The first exactly dateable reference to it that I can find is as the acronym "WWW" used several times in an HTML file of 4 Dec 90 (/StoringLinks.html), but the second proposal, dated October 1990 and 12 November 1990, is titled "WorldWideWeb — Proposal for a HyperText Project". The graphics files for this paper were modified on 23 October 90. This seems to indicate that the name WorldWideWeb was chosen beween 16 and 23 October 1990, though it's possible that the browser retained the name for some time after the project name was chosen. The first TheProject.html had been created by the time of the proposal paper, and was available on cernvax.
The AUTHOR tag was only used once, in the earliest HTML fragment:
<TITLE>Documnts found with keywords COPY TAPE VMS IBM</TITLE> <AUTHOR HREF=pollermann.who.cern.ch></AUTHOR> The following 20 documents have these keywords. <A HREF=min15.hmins.find.cern.ch TYPE=refersto>Minutes of the HGQI meeting of 21-July</A> <A HREF=min14.hmins.find.cern.ch TYPE=refersto>Minutes of the HGQI meeting of 14-July</A> <A HREF=min13.hmins.find.cern.ch TYPE=refersto>Minutes of the HGQI meeting of 2-July</A> <P> <A HREF=copytape.vmhelp.find.cern.ch TYPE=refersto>The CMS COPYTAPE command</A>
This is from around 20 Aug 90. Though both AUTHOR and TITLE are from the CERN SGML (PDF), A is not and neither is the HREF attribute. AUTHOR had a required REFID in CERN SGML, and HREF appears to be TimBL's invention. The main inspiration for A seems to have been IREF, an index reference, which also required a REFID attribute. Note that the links here are typed, which is something we find in MarkUp.wn too. In MarkUp.wn the attribute is REL, not TYPE. Later, TYPE would be used again and then, ironically, REL which became standard.
The idea of LINK seems to be that if you link to the LINK with an ANCHOR, the LINK redirects you, though the meaning of "but the link has no specific anchor within the document" isn't very clear. Most likely the idea is that LINK does not span any text like A, and therefore doesn't give you any clickable link, as with the modern LINK. The following, however, was also apparently intended to work:
Written by <A HREF=#1>CTB</A>. <LINK HREF=People.html#11 ID=1>
One interesting thing is that the definition literally says that LINK is similar to ANCHOR. Was A once named ANCHOR? The earliest fragment of HTML, from before the code was written, uses an A tag and not ANCHOR. The oldest HTML document on the web dates from about two weeks after the first web code, and contains "<a href=WhatIs.html>hypertext</a>", which seems to indicate that A was around from the beginning. I've not found any HTML document which uses ANCHOR instead of A. Presumably, then, TimBL was just expanding the name by way of explanation and perhaps to connect it with the LINK metaphor.
I suspect it's a coincidence that LINK appears in HTTP/Ex1.html and DATE in HTRQ/Request.html, both of which are by Carl Barker (CTB), on 16 Apr 1992 and 11 Jun 1992 respectively, as part of his request markup format. Perhaps, though, he knew about the earlier tags.
June 1993
Created January 2011, by Sean B. Palmer.